DOCUMENT / LOG-20250614-WHY-SVM-STIL
Margins, Kernels, and Control: Why Support Vector Machines Are Still Worth Learning
An intuitive guide to support vector machines, margins, support vectors, kernels, C, gamma, overfitting, and when SVMs remain a strong model choice.
CONTENTS20
Machine learning today is dominated by deep learning, large language models, and increasingly complex systems.
But before neural networks became the default answer to every problem, one algorithm dominated machine learning competitions, academic research, and many real-world applications:
Support Vector Machines (SVMs).
Even today, SVMs remain one of the best models to learn if you want to understand how classification works. They are mathematically elegant, relatively easy to train, and often perform surprisingly well on small and medium-sized datasets.
If you’re new to machine learning, SVMs teach several important ideas:
- Decision boundaries
- Generalization
- Overfitting
- Regularization
- Feature spaces
- Optimization
Understanding SVMs will make many other machine learning algorithms easier to understand.
What Problem Does an SVM Solve?
Imagine you have two groups of points:
- Apples
- Oranges
Your goal is to draw a boundary that separates them.
Many different lines could separate the two groups.
The question is:
Which line should we choose?
An SVM chooses the boundary that leaves the largest possible gap between the two classes.
This gap is called the margin.
Instead of merely separating the data, the SVM tries to separate it with the greatest amount of safety.
Why Does Margin Matter?
Suppose you train a classifier on historical data.
Tomorrow, new data arrives.
Those new observations will never be identical to your training data.
Measurements contain noise. Sensors have errors. Humans make mistakes.
If your decision boundary sits too close to the training examples, even a small change can produce incorrect predictions.
A larger margin creates a buffer zone.
That buffer helps the model remain stable when new data arrives.
In practice:
- Larger margins often generalize better.
- Smaller margins often overfit more easily.
This idea is one of the central concepts in machine learning.
What Are Support Vectors?
The name “Support Vector Machine” comes from the observations that define the margin.
These special observations are called support vectors.
Think of them as the points closest to the decision boundary.
Interestingly, most training points do not directly determine the final boundary.
Only a relatively small subset of critical points matters.
If you remove a point that is far from the boundary, the model may barely change.
If you remove a support vector, the boundary can shift significantly.
This is one reason SVMs are often efficient and robust.
Linear SVMs
The simplest SVM draws a straight line.
For two-dimensional data, that line might look like this:
Class A | Class B
x | o
x | o
x | o
------------|-------------When the classes can be separated by a straight line, a linear SVM is often extremely effective.
Linear SVMs are:
- Fast
- Easy to train
- Easy to interpret
- Good for high-dimensional data
Many text-classification systems historically used linear SVMs with great success.
When Data Is Not Linearly Separable
Real-world data is rarely this neat.
Consider the famous “two moons” dataset.
The classes wrap around each other.
No straight line can separate them correctly.
This is where kernels become useful.
Understanding Kernels Without the Magic
Many explanations say:
SVMs project data into higher dimensions.
This is technically correct, but it can sound mysterious.
A simpler way to think about kernels is:
Kernels give SVMs the ability to draw curved decision boundaries.
Instead of forcing a straight line, the model can learn more flexible shapes.
Different kernels create different types of boundaries.
Common kernels include:
| Kernel | Typical Use |
|---|---|
| Linear | Data is mostly linearly separable |
| Polynomial | Curved relationships |
| RBF | General-purpose nonlinear problems |
| Sigmoid | Rarely used in practice |
The most popular kernel is the RBF (Radial Basis Function) kernel.
If you are unsure where to start, start with RBF.
The Two Most Important Hyperparameters
One reason SVMs remain attractive is their simplicity.
For an RBF kernel, you usually spend most of your time tuning only two parameters:
Cgamma
Understanding these two values is often enough to get good performance.
Understanding C
C controls how strongly the model tries to avoid training errors.
Small C
A small value allows some mistakes.
The model prefers a wider, softer margin.
This usually produces a simpler classifier.
Benefits:
- Better generalization
- Less overfitting
- Smoother boundaries
Large C
A large value penalizes mistakes heavily.
The model tries harder to classify every training example correctly.
Benefits:
- Lower training error
Risks:
- Overfitting
- Reduced tolerance to noisy observations
- Poor performance on unseen data
A useful mental model:
Ccontrols how much you trust the training data.
Understanding gamma
gamma determines how far the influence of each training point extends.
Small gamma
Each point influences a large area.
The resulting boundary is smooth and simple.
Large gamma
Each point influences only its immediate neighborhood.
The boundary becomes highly detailed.
Benefits:
- Can fit complex patterns
Risks:
- Overfitting
- Sensitivity to noise
A useful mental model:
gammacontrols how local the model’s decisions become.
Visualizing the Effect of C
The animation below keeps gamma fixed while increasing C.

As C increases, the model tolerates fewer mistakes, the soft margin becomes less forgiving, and the classifier can become more sensitive to the training data.
Visualizing the Effect of gamma
The animation below keeps C = 1.0 fixed while varying gamma.
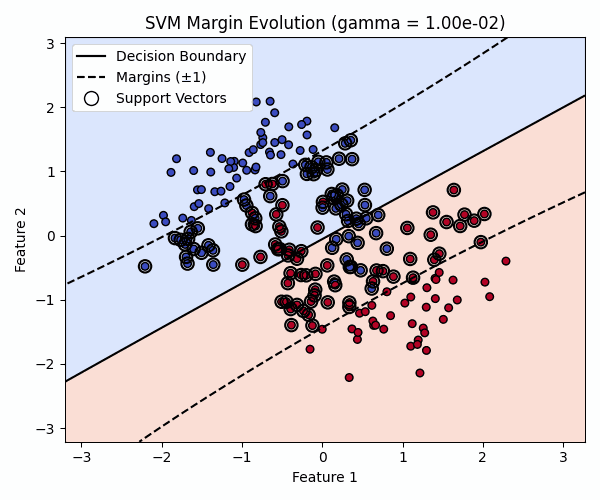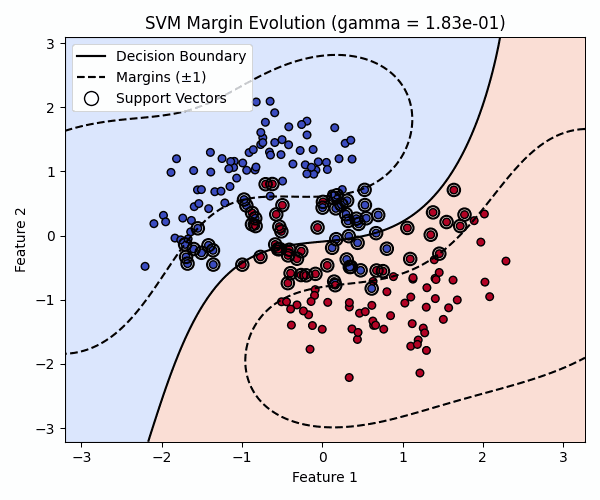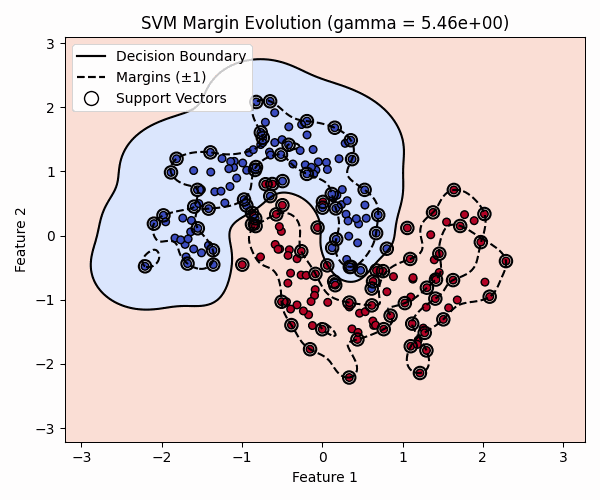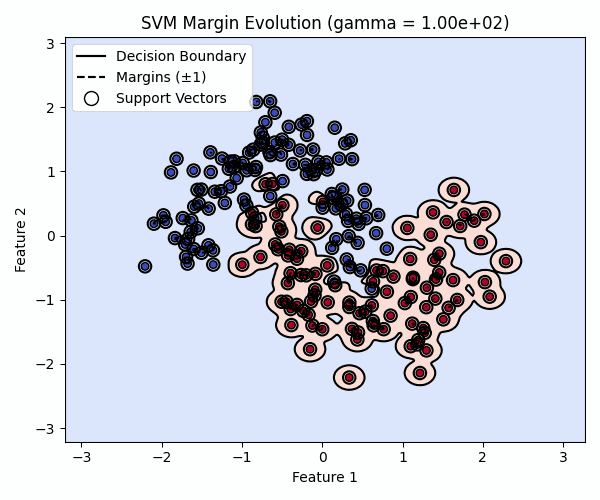
As gamma increases, decision boundaries become more flexible and can eventually overfit the training data.
An Important Practical Rule: Scale Your Features
Before training an SVM, feature scaling is usually essential.
Suppose your dataset contains:
- Age: 18–80
- Income: 20,000–500,000
Without scaling, income dominates the distance calculations.
Because SVMs rely heavily on distances, this can significantly hurt performance.
A common preprocessing pipeline is:
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
model = make_pipeline(
StandardScaler(),
SVC(kernel="rbf")
)If your SVM performs poorly, the first thing to check is often feature scaling.
When SVMs Work Well
SVMs are often a strong choice when:
- The dataset is small or medium-sized
- The number of features is large
- The classes are reasonably separable
- You need strong baseline performance quickly
- Training speed matters
Examples include:
- Text classification
- Spam detection
- Bioinformatics
- Medical diagnostics
- Gene expression analysis
Historically, SVMs were extremely popular in genomics because researchers often had thousands of features but relatively few samples.
When SVMs Struggle
SVMs are not perfect.
They can struggle when:
- Datasets become extremely large
- Training data contains millions of samples
- Features are noisy and poorly engineered
- Interpretability is critical
- Deep learning can exploit large amounts of data
For image recognition, speech recognition, and modern language models, neural networks generally outperform SVMs.
Want to Try It Yourself?
You can reproduce both animations using the same script used for this post:
The script:
- generates a noisy two-moons dataset
- scales the features with
StandardScaler - trains an RBF SVM
- sweeps across different values of
C - sweeps across different values of
gamma - saves two GIFs showing how the decision boundary changes
Install the dependencies:
python -m pip install numpy matplotlib imageio scikit-learnThen run:
python svm_c_gamma_moons.pyThe script will generate:
svm_moons_c_evolution.gif
svm_moons_gamma_evolution.gifTry experimenting with:
- Different kernels
- Different datasets
- Different values of
C - Different values of
gamma - Different
noiselevels inmake_moons()
Watching the decision boundary evolve is one of the best ways to build intuition.
Key Takeaways
If you remember only three things about SVMs, remember these:
- SVMs try to maximize the margin between classes.
- Support vectors are the critical points that define the boundary.
Candgammacontrol the balance between simplicity and complexity.
These ideas appear throughout machine learning, even in models that look completely different.
Learning SVMs is not just about learning one algorithm.
It is about learning how machine learning models balance accuracy, complexity, and generalization.
And that lesson remains valuable no matter what model you use next.