Conformalized Quantile Regression (CQR): Prediction Intervals That Breathe With Your Data
Most machine learning models predict a single number.
For example:
House price = $350,000
Gene expression = 12.4
Temperature tomorrow = 27.3°C
But a prediction without uncertainty is often incomplete.
A model may predict the same value in two situations:
- One where it is highly confident.
- Another where the data is noisy and unpredictable.
Treating those situations as equally reliable can lead to poor decisions.
This is where Conformalized Quantile Regression (CQR) becomes useful.
CQR produces prediction intervals that automatically widen in noisy regions and tighten in stable regions, while still providing statistical coverage guarantees.
Confidence Is Local, Not Global
When we say a model is “confident”, what do we actually mean?
Confidence is usually not a property of the model itself.
It is a property of where the model is making the prediction.
Some parts of the data are predictable:
- Measurements are stable.
- Patterns repeat.
- Noise is low.
Other parts are much harder:
- Variance increases.
- Noise dominates the signal.
- Small input changes produce large output changes.
If you work with biological data, you see this often.
For example, in gene expression data, low and moderate expression levels may behave nicely, while high-expression regions become increasingly noisy.
Yet many systems still use:
- One global standard deviation.
- One fixed-width confidence interval.
- One uncertainty estimate applied everywhere.
Reality is rarely that simple.
What we really want is:
Uncertainty that grows when the data becomes noisy and shrinks when the data becomes predictable.
That is exactly what CQR tries to achieve.
The Problem With Fixed-Width Error Bars
Many uncertainty methods assume that variability is constant across the entire dataset.
This assumption is called homoscedasticity.
In practice, many real-world systems are heteroscedastic, meaning that uncertainty changes across the input space.
Examples include:
- Single-cell gene expression.
- Financial forecasting.
- Demand prediction.
- Clinical risk models.
- Weather forecasting.
A fixed-width interval assumes uncertainty is the same everywhere.
Real data often disagrees.
Stop Predicting Points. Start Predicting Ranges.
Traditional regression predicts:
y = f(x)
Quantile regression predicts boundaries instead.
For example:
Lower bound: q_low(x)
Upper bound: q_high(x)
These bounds might correspond to:
- The 5th percentile.
- The 95th percentile.
Together they form a prediction interval:
[q_low(x), q_high(x)]
Unlike fixed-width intervals, the distance between these bounds can change depending on the local structure of the data.
Noisy regions naturally produce wider intervals.
Stable regions naturally produce narrower intervals.
This already gives us adaptive uncertainty.
Unfortunately, there is still a problem.
Quantile Regression Alone Is Not Enough
Suppose a model predicts a 90% interval.
Does that interval actually contain the true value 90% of the time?
Not necessarily.
Quantile regression learns interval boundaries, but it does not guarantee coverage.
This is where conformal prediction enters the picture.
Conformal prediction adds a calibration step that measures how well the predicted intervals perform on unseen data.
Instead of trusting the model blindly, we evaluate its mistakes and correct them.
How Conformal Calibration Works
The process is surprisingly simple.
Step 1: Split the Data
We use three datasets:
- Training set
- Calibration set
- Test set
The calibration set is never used for training.
Its only purpose is to measure how well the intervals behave.
Step 2: Train Quantile Models
Train two models:
q_low(x)
q_high(x)
For example:
- 5th percentile model
- 95th percentile model
Together they define:
[q_low(x), q_high(x)]
Step 3: Measure Interval Errors
For each calibration sample:
score_i = max(
q_low(x_i) - y_i,
y_i - q_high(x_i)
)
This score answers one question:
How much did the interval miss the true value?
Interpretation:
- Score <= 0 → prediction already contains the truth.
- Score > 0 → interval was too narrow.
The larger the score, the more correction we need.
Step 4: Compute the Conformal Correction
Collect all calibration scores:
S = {score_1, score_2, ..., score_n}
Sort them:
S_sorted = sort(S)
Compute:
k = ceil((n + 1) * (1 - alpha))
Then:
q_hat = S_sorted[k]
Where:
n= number of calibration samplesalpha= target error rate
For example:
- alpha = 0.10
- Desired coverage = 90%
Step 5: Expand Future Intervals
Finally:
[q_low(x) - q_hat,
q_high(x) + q_hat]
This simple correction gives finite-sample coverage guarantees under standard conformal assumptions.
In short:
- Quantile regression shapes the interval.
- Conformal calibration makes it trustworthy.
What Adaptive Uncertainty Looks Like
Consider a toy dataset:
X = Uniform(0, 10)
signal = 2X sin(X) + 10
noise_sd = 0.5 + 0.5 * X
y = signal + Normal(0, noise_sd)
Notice that noise increases with X.
Low values are relatively stable.
Higher values become progressively noisier.
A fixed-width interval struggles here.
It is either:
- Too wide in low-noise regions.
- Too narrow in high-noise regions.
CQR adapts automatically.
The interval grows where uncertainty grows.
Visual Example
The animation below compares:
- CQR prediction intervals
- Fixed-width prediction intervals
as a sliding window moves across the data.
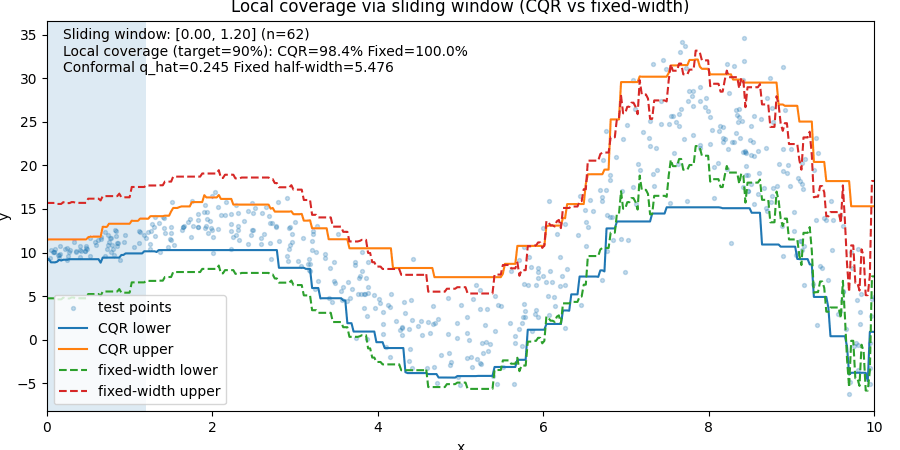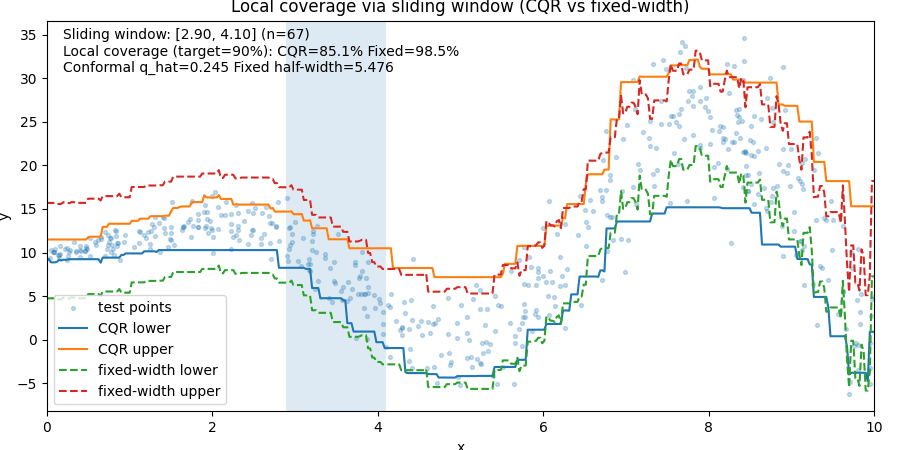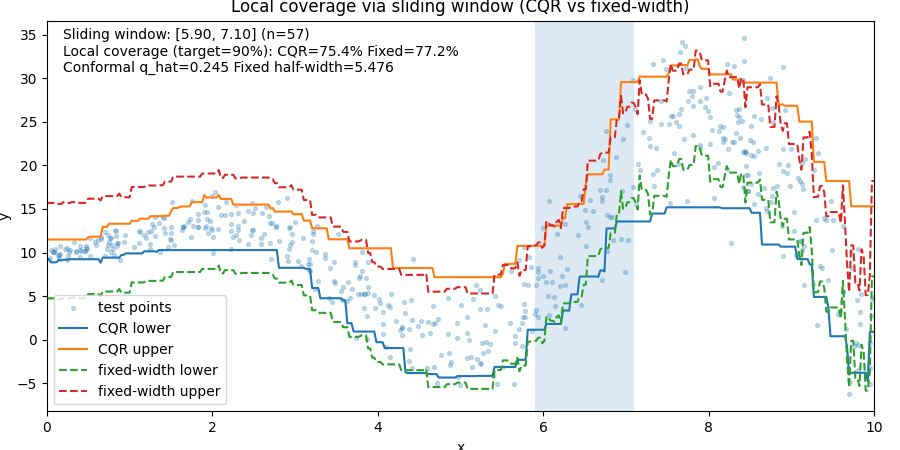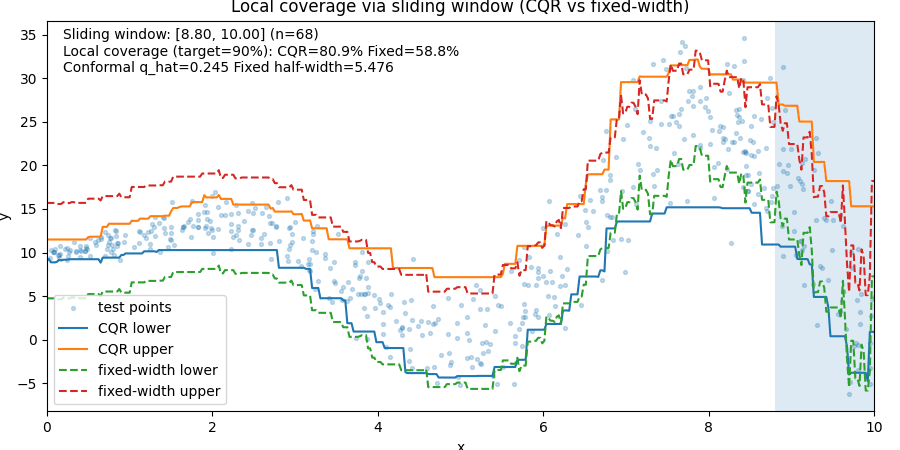
Notice what happens:
- In stable regions, fixed-width intervals waste space.
- In noisy regions, fixed-width intervals often fail.
- CQR adjusts to local uncertainty.
The important lesson is:
Fixed-width intervals achieve coverage by being globally conservative.
CQR achieves coverage by adapting to where uncertainty actually exists.
Why This Matters In Bioinformatics
Many biological systems are naturally heteroscedastic.
Examples include:
- Gene expression prediction.
- Protein abundance estimation.
- Single-cell modeling.
- Trajectory inference.
- Experimental measurement pipelines.
Different biological states often have different levels of variability.
Using one uncertainty estimate everywhere can hide important signals and failure modes.
CQR provides a practical way to model uncertainty without assuming a specific probability distribution.
Common Caveats
Like every method, CQR has limitations.
Quantile Crossing
Sometimes:
q_low(x) > q_high(x)
This creates an invalid interval.
Always check for this and correct it if necessary.
Coverage Is Marginal
Conformal guarantees are typically marginal.
This means:
90% coverage overall
does not necessarily mean:
90% coverage in every subgroup
Conditional coverage remains an active research area.
Distribution Shift
Conformal methods assume calibration and deployment data come from similar distributions.
If the environment changes substantially:
- New populations
- New instruments
- New protocols
then recalibration may be necessary.
Minimal Implementation
import numpy as np
from sklearn.ensemble import GradientBoostingRegressor
def cqr_fit_predict_intervals(
X_train, y_train,
X_cal, y_cal,
X_test,
alpha=0.10,
random_state=0
):
q_low = alpha / 2
q_high = 1 - alpha / 2
low_model = GradientBoostingRegressor(
loss="quantile",
alpha=q_low,
random_state=random_state
)
high_model = GradientBoostingRegressor(
loss="quantile",
alpha=q_high,
random_state=random_state
)
low_model.fit(X_train, y_train)
high_model.fit(X_train, y_train)
low_cal = low_model.predict(X_cal)
high_cal = high_model.predict(X_cal)
lo = np.minimum(low_cal, high_cal)
hi = np.maximum(low_cal, high_cal)
scores = np.maximum(
lo - y_cal,
y_cal - hi
)
n = len(scores)
k = int(np.ceil((n + 1) * (1 - alpha))) - 1
k = np.clip(k, 0, n - 1)
qhat = np.sort(scores)[k]
low_test = low_model.predict(X_test)
high_test = high_model.predict(X_test)
lo_t = np.minimum(low_test, high_test)
hi_t = np.maximum(low_test, high_test)
lower = lo_t - qhat
upper = hi_t + qhat
return lower, upper, qhat
When Should You Use CQR?
CQR is a good choice when:
- You need prediction intervals, not just point predictions.
- Uncertainty changes across the input space.
- You do not want strong distributional assumptions.
- You want statistically valid coverage.
- You need a model-agnostic solution.
It works with many underlying models, including:
- Gradient boosting
- Random forests
- Neural networks
- XGBoost
- LightGBM
The conformal layer is separate from the predictive model.